
大模型炙手可热,不过正在形成两大阵营。
一方面,是越来越强的云侧大模型。从文生视频的Sora,到最近在实时语音交互上令人印象深刻的GPT-4o,以及国内上百款大模型都是这样。在华为开发者大会2024(HDC 2024)上,华为云重磅发布的盘古大模型5.0,在多模态理解、复杂逻辑推理等方面的表现,更是备受瞩目。

另一方面,是大模型走向端侧。包括华为、荣耀、OPPO、vivo等手机厂商,以及联想等PC厂商,都推出了AI端侧大模型。最近举行的WWDC24上,苹果也发布了本地运行的Apple Intelligence。
那么问题来了,端侧大模型和云侧大模型到底谁代表着未来?AI时代的发展方向到底是什么?
大模型时代的终极范式
“深度学习之父” Geoffrey Hinton曾经畅想过这样的场景:“会有一个阶段,一旦某个AI系统训练完毕,我们会将其运行在非常低功耗的系统上,所以,如果你想让你的烤面包机能和你对话,你需要一个只花费几美元的芯片,而且它能运行像ChatGPT这样的程序。”
端侧大模型之所以会出现,归结起来有这么几个原因:一是云侧大模型推理成本比较高;二是在端侧运行的大模型可以保护数据隐私;三是在一些没有网络连接的场景下,可以使用本地算力来支持大模型的运行。IDC预测,到2026年中国市场近50%的终端设备处理器将带有AI引擎,由此可以看到端侧大模型的发展迅速。
不过,端侧大模型也有其不足。IDC中国高级分析师郭天翔表示,目前端侧的算力要求比较高,功耗比较大,更为重要的是端侧大模型的参数量级无法和云侧的通用大模型相比。纵观市面上的大模型,相比云测大模型动辄百亿、千亿参数,端侧大模型大多参数量级比较小,如苹果的端侧大模型为30亿参数。
目前业界越来越认同,端侧大模型和云侧大模型并不是竞争关系,而是协同关系。部分智能推理任务或者推理任务的部分阶段放到端侧进行处理,可以发挥端侧大模型本地即时处理的优势,而且用户原始数据不离开本地,可以保护数据安全隐私。同时,需要更强能力、更深思考的时候,可以使用云侧大模型。双方优势互补,相得益彰,最大程度地发挥端侧大模型和云侧大模型的优势。

举个例子,如果你对某篇文章做摘要,可以使用端侧大模型,而要写一篇论文查阅该领域的历史性资料,就只能使用云侧大模型。IDC在预测2024年AI发展趋势时,也将端云结合确定为其中之一,其指出端侧大模型的安全性和及时性与云侧大模型的丰富功能和算力将实现很好结合。
以华为为例,小艺背后的大模型就拥有端侧和云侧两种形态,可以针对不同设备和场景的需求进行处理。端侧大模型会对用户请求和上下文信息做预处理,然后将需求发到云端,最大化发挥端侧的速度与云侧的强大。同样,苹果入局大模型,也是采用端云协同的方式。
在HDC 2024上,鸿蒙原生智能(Harmony Intelligence)发布,就是采用端云协同的架构。端侧的个人数据与用户意图,和云侧的智能中枢互相配合,高效协同。

端云协同才是大模型时代的终极范式。
端云协同的大模型,有多难?
不过,端云协同说起来容易,实际实现起来难度很大。
端侧大模型的实现路径大致是这样的,通常是云侧大模型通过剪枝、量化、蒸馏等模型压缩和加速技术,给大模型减重,然后再根据终端的特点和用户需求进行针对性的训练。例如,华为小艺的端侧大模型就重点针对语音对话、设备操作、购物、生活常识等场景进行训练,而且还对提示词和输出格式进行了压缩,将推理时延缩短了一半。
显然,这个过程就要求厂商对于云侧大模型和端侧大模型都需要有深刻理解和丰富经验。而且,如何将任务在两种大模型间进行分配,如何实现端侧和云侧的良好配合,如何保护数据隐私等等,对于厂商来说都是极大的考验。华为常务董事、终端BG董事长、智能汽车解决方案BU董事长余承东表示,华为早在2017年就开启Mobile AI时代,持续耕耘终端AI体验创新,从2018-2020年的个人终端AI化,以及2021-2022年的全场景设备AI化,到2023-2024年以AI大模型赋能终端,都是这样。

站在这个角度看华为云,就可知其在端云协同上的独特性。因为华为几乎是业界唯一同时拥有云侧大模型和端侧大模型,以华为云作为统一云底座,打造了昇腾、鲲鹏、鸿蒙、欧拉、GaussDB等根技术及相关生态,并实现领先的厂商。在云侧,早在2021年华为就发布了盘古大模型,包括NLP大模型和CV大模型,并在这几年持续迭代,最新发布的盘古大模型5.0最大的特点是在多模态上有了突飞猛进的进步,能够更好更精准地理解物理世界,包括文本、图片、视频、雷达、红外、遥感等更多模态。在图片和视频识别方面,可支持10K超高分辨率;在内容生成方面,采用业界首创的STCG(Spatio Temporal Controllable Generation,可控时空生成)技术,聚焦自动驾驶、工业制造、建筑等多个行业场景,可生成更加符合物理规律的多模态内容。

在端侧,华为在盘古L0大模型的基础上,专门针对终端消费者场景中涉及的数据进行了精细调优,构建出一个L1的对话大模型,应用到了小艺上,小艺在端侧大模型的加持下,不仅可以通过自然语言对话更聪明地理解并执行用户指令,而且可以实现文本生成、摘要总结、多语种翻译等功能,堪称是一个高效的生产力工具。同时,小艺是越用越懂你,可以通过学习不断进步,俨然是一个私人智能助手。
在华为自主新一代盘古大模型5.0的加持下,小艺的能力也得到全面提升,拥有上万亿tokens的知识量,可以智能感知23类主要场景,提供300多种重点服务,任务推理规划的成功率高达90%。

今年4月华为发布的华为MateBook X Pro不仅首次应用盘古大模型,还精选100+智能体,用户可以一键直达丰富的AI应用。在热销的问界M9上,车载智慧助手小艺在AI大模型的加持下具有用车知识问答、热点资讯总结、百科知识问答等功能,是车主用车过程中的得力助手。
在华为Mate60系列手机中备受用户好评的AI云增强,同样体现出华为云在端云协同上的能力。用户拍摄图片后,可以点击图片右上角的魔法棒图标,从而对照片进行智能分析,并将照片上传到云端进行优化,提升照片的清晰度和美感度。据了解,这项突破手机硬件限制的独特功能,背后是通过华为云KooVerse全球存算网调用云端强大的算力,在云端进行AI推理,从而让用户在手机上实现专业级的照片效果。
除了云拍照增强外,云助端的典型场景还有云助小艺及云手机等,云助小艺可以调用云上千万级参数大模型,支撑千万级用户在线推理,语音对话、AIGC在线创作及个性化推荐能力全面提升;云手机场景下,通过华为云全球存算网让算力在近端部署,端到端时延<150ms,全面助力鸿蒙生态的繁荣。
事实上,盘古大模型的架构天然契合端云协同的特性。盘古大模型并不是一个大模型,而是一个大模型系列,包括“5+N+X”三层架构:L0层包括自然语言、视觉、多模态、预测、科学计算五大基础大模型,可以满足行业场景中的多种技能需求;L1层是N个行业大模型,基于通用大模型训练;L2层是更多细化场景的模型,场景包括政务热线、网点助手、台风路径预测等。在HDC 2024上,可以看到盘古大模型5.0包含不同参数规格的模型,以适配不同的业务场景。十亿级参数的Pangu E系列可支撑手机、PC等端侧的智能应用;百亿级参数的Pangu P系列,适用于低时延、高效率的推理场景;千亿级参数的Pangu U系列适用于处理复杂任务;万亿级参数的Pangu S系列超级大模型能够帮助企业处理更为复杂的跨领域多任务。

盘古大模型的三层架构完全解耦设计,从而可以快速适配、快速满足行业需求。华为之所以可以快速从L0的盘古大模型训练出L1的小艺端侧大模型就是如此。
佛经中常有“须弥纳芥子”、“芥子纳须弥”的说法,巨大如须弥山这样的存在都可以放入芥子这样微小的东西里面,意指佛法博大精深,以及修行之难。将云侧大模型放到端侧,不也是如此吗?不仅要放进去,而且要能满足特定场景需求,还要实现云侧和端侧的协同配合,对厂商考验之大可想而知。
端云协同的混合大模型才是AI的未来
总而言之,端云协同的混合大模型才是AI的未来。
混合大模型,不仅可以结合端侧和云侧的各自优势,更是可以形成一种彼此促进的飞轮效应。云侧大模型可以向端侧大模型输出能力,而端侧大模型可以向云侧大模型反馈执行成效和端侧新知识,进而促进云侧大模型不断进化,彼此推动,飞轮越转越快。
这种混合大模型,不仅适用于C端,更是适用于B端。实际上,企业自己的专有大模型就像手机或者PC上的端侧大模型一样,拥有更好的安全以及更低的时延。对于企业来说,混合大模型既能打消其对于数据保护的顾虑,又能兼顾大模型在能力上的优势。如果说手机和PC上的混合大模型加速了大模型进入寻常百姓家,那么,无疑,端云协同的大模型可以加速大模型在千行万业上的落地。
在这方面,盘古大模型无疑具有独特优势。就像华为常务董事、华为云CEO张平安所说,“一直以来,华为云盘古大模型都坚定的聚焦行业,在解难题、做难事的道路上不断攻坚克难,砥砺前行”,盘古大模型生来就是深入千行万业的具体场景中,帮助客户解决难题。
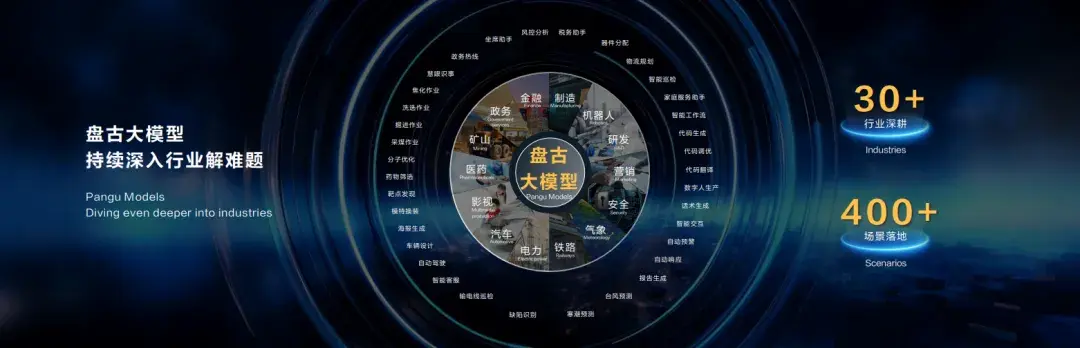
一方面,L0层的盘古大模型持续进化,最新发布的盘古5.0在多模态、全系列、强思维三方面进行升级,越来越强大;另一方面,从L0到L1,盘古大模型可以结合行业公开数据训练出行业通用大模型,也可以基于行业客户自有数据训练出企业专有大模型;L2层则为客户提供“开箱即用”的模型服务。不同层级的大模型也是彼此促进,形成飞轮效应。
可以预计,越来越多的企业、行业都将能在端云协同的混合大模型的加持下,加速数字化、智能化。混合大模型,必将为AI落地千行万业按下加速键。
本文来自投稿,不代表创造权威IP 赋能创业者——IP百创立场,如若转载,请注明出处:创造权威IP 赋能创业者——IP百创
 微信扫一扫
微信扫一扫 
