
近日,昆仑万维携手新加坡南洋理工大学成功开发了一个名为Q*的算法,能够显著提升现有大模型的推理能力。在GSM8K数据集上,Q*帮助Llama-2-7b提升至80.8%的准确率,超越了ChatGPT;在MATH数据集上,Q*帮助DeepSeek-Math-7b提升至55.4%的准确率,超越了Gemini Ultra;在MBPP数据集上,Q*帮助CodeQwen1.5-7b-Chat提升至77.0%的准确率,缩小了与GPT-4的编程水平差距。
Q*能够帮助小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,这一算法不仅大幅提升了小模型的性能,还显著降低了计算资源的需求,为人工智能的广泛应用带来了全新可能,开创了高效智能的新纪元。
项目论文《Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning》已公开发布。
论文链接:https://arxiv.org/abs/2406.14283

打破OpenAI封锁 提升现有模型能力
自OpenAI的Q*项目曝光后,引发业内众多讨论。据现有信息汇总,Q*项目被视作OpenAI在探索人工通用智能(Artificial General Intelligence, AGI)道路上的一次重大尝试,有望在包括数学问题解决能力、自主学习和自我改进等多个层面对人工智能技术带来革新性突破。
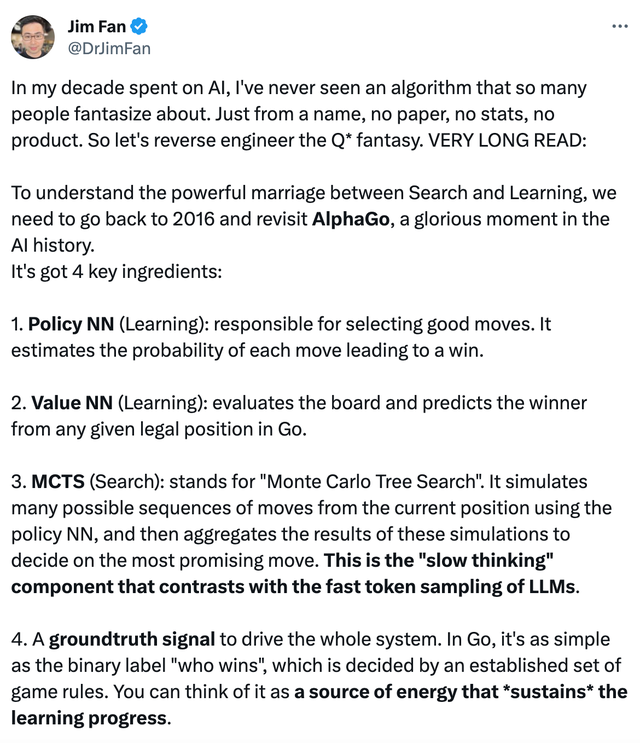
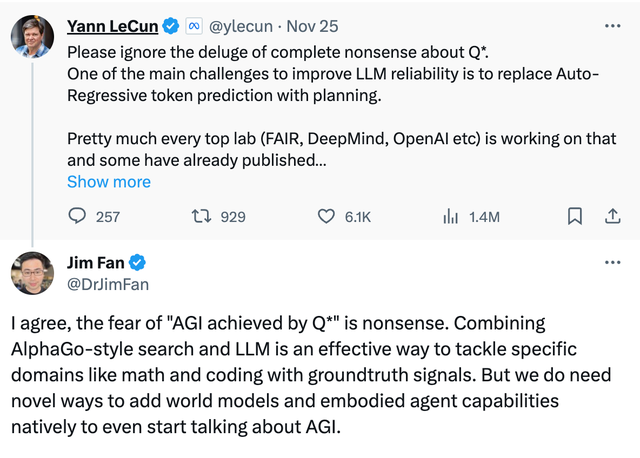
(英伟达科学家Jim Fan、图灵奖得主Yann LeCun等参与讨论OpenAI的Q*实现方式)

(Meta科学家田渊栋则认为Q*是Q-learning和A*的结合,且天然地适合推理任务,尤其在数学推理方面)
不过迄今为止OpenAI没有公开关于Q*算法的具体细节,其效果究竟如何我们并不得而知。
昆仑万维自Q*项目曝光以来,一直密切关注Q*的动向,且在第一时间就成立研究小组尝试开发自己的Q*算法,希望打破OpenAI的封锁,提升现有开源模型的推理能力。经过数月的尝试,团队提出了一种新颖的Q*框架,并且帮助现有开源模型在GSM8K、MATH和MBPP数据集上,分别超越了ChatGPT和Gemini Ultra。
复杂推理任务全盘规划
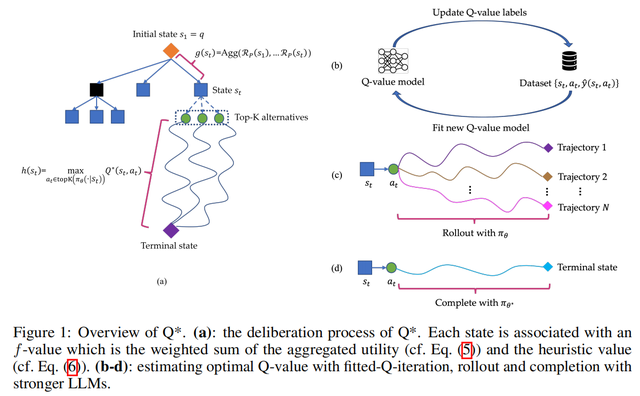
在《Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning》论文中,研究人员首先将大语言模型的推理轨迹分解为若干个状态,对于每一个状态,参考DeepCubeA中的设计,通过将定义Path Cost的g(s_t)函数和定义Accumulated Reward的Q*(s_t, a_t)集成到同一个f(s_t)函数内,实现了对历史状态收益和未来期望收益的综合考虑。最后利用A*搜索算法对状态进行最佳优先搜索,实现了对复杂推理任务的全盘规划,从而提升开源模型在推理任务上的性能。
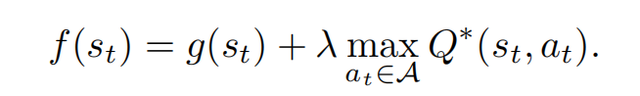
其中g(s_t)表示当前轨迹中的多个历史状态,既{s1,…,s_t},的聚合收益。
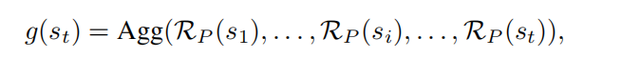
具体g(s_t)的函数形式可以通过人为定义,例如判断当前代码是否符合语法规则等,或者通过构建Process Reward Model (PRM) 进行监督学习得到;g(s_t)中的聚合方式可以为求和,最大值,最小值等。
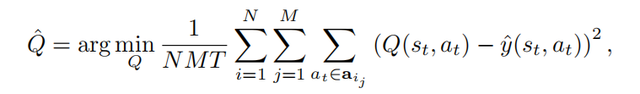
为了获得状态-动作对(s_t, a_t)
的最优Q值以实现规划,研究人员在当前LLM策略生成的数据上通过监督学习的方式训练了一个代理Q值模型

。训练过程中的真实标签
可以由三种不同的方式得到,包括离线强化学习,蒙塔卡罗采样估计和利用更强大的语言模型补全。
实验结果表明,昆仑万维本次所提出的Q*框架,可以显著地提升LLM的推理能力,在GSM8K数据集上,Q*帮助Llama-2-7b提升至80.8%的准确率,超越了ChatGPT;在MATH数据集上,Q*帮助DeepSeek-Math-7b提升至55.4%的准确率,超越了Gemini Ultra; 在MBPP数据集上,Q*帮助CodeQwen1.5-7b-Chat提升至77.0%的准确率,缩小了与GPT-4的编程水平差距。
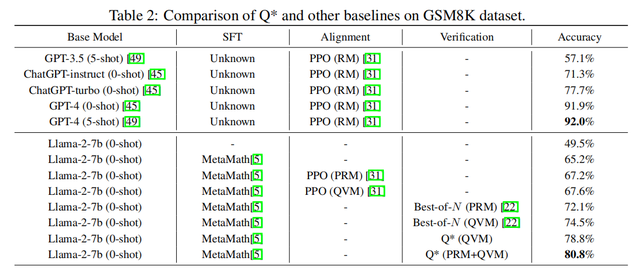
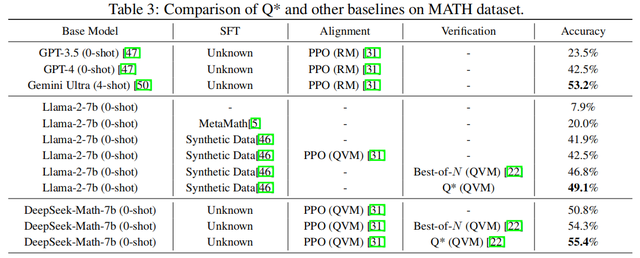
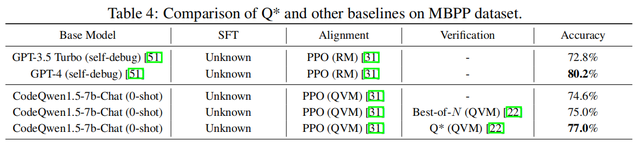
研究证明,Q*能够帮助参数量仅为7b的小模型达到参数量比其大数十倍甚至百倍模型的推理能力,大幅提升模型的性能,并显著降低了计算资源的需求。目前,Q*的研究尚在初级阶段,算法在各个环节还有进一步的改进空间。未来,昆仑万维会继续深入此项研究,不断提升国产开源模型推理能力,打破OpenAI闭源封锁,为人工智能前沿技术发展带来全新可能。
本文来自投稿,不代表创造权威IP 赋能创业者——IP百创立场,如若转载,请注明出处:创造权威IP 赋能创业者——IP百创
 微信扫一扫
微信扫一扫 
